RabbitMQ and Oslo.messaging
本博客所有文章采用的授权方式为 自由转载-非商用-非衍生-保持署名 ,转载请务必注明出处,谢谢。
声明:
本博客欢迎转发,但请保留原作者信息!
新浪微博:@Lingxian_kong
博客地址:孔令贤的博客
微信公众号:飞翔的尘埃
知识星球:飞翔的尘埃
内容系本人学习、研究和总结,如有雷同,实属荣幸!
写在前面的话:
关于OpenStack中的消息队列,我最早在2012年就做过相应的分析,但当时的代码与如今相比,结构已经发生了巨大的变化。但是,万变不离其宗,内部最基本的实现原理却没有发生大的变动。于是,我连着吃了两年多的老本。直到最近做项目时,碰到了ack相关的一些疑问,回过头来想根据代码排错时,发现已经完全弄不明白代码之间的跳转了,特别是oslo.messaging库,做了太多的封装和抽象。所以,决定还是花点时间和精力,再次把消息队列相关的知识做个梳理。而每次的梳理,我都会有新的体会和对问题新的看法,这也是我坚持写技术博客的主要原因之一。当然,以我一贯的风格,你会看到更多对实现原理的分析和总结。
基本概念
建议先把这个教程看一遍:https://www.rabbitmq.com/tutorials/tutorial-one-python.html
Roles
producer, exchange, queue, message, consumer
Producer
RPC ways. In order to receive a response the client needs to send a ‘callback’ queue address with the request. e.g. specify properties=pika.BasicProperties(reply_to = callback_queue_name) when publishing messages. It will create a callback queue for every RPC request, which is not efficient, to solve the problem, we can use correlation_id to create a single callback queue per client.
If producer needs to know if message reached at least one queue, it can set the mandatory flag on a basic.publish, ensuring that a basic.return will be sent back to the client if no queues were appropriately bound.
Exchange
In RabbitMQ a message can never be sent directly to the queue, Instead, the producer can only send messages to an exchange, There are a few exchange types available: direct, topic, headers and fanout, the routing-key’s value is ignored for fanout exchanges.
Topic exchange is powerful and can behave like other exchanges.
Queue
Queues can optionally be made mirrored across multiple nodes. Each mirrored queue consists of one master and one or more slaves, with the oldest slave being promoted to the new master if the old master disappears for any reason.
Exclusive queues will be deleted when the connection that declared them is closed
Consumer
By default, RabbitMQ will send each message to the next consumer listening to the same queue, in sequence. This way of distributing messages is called round-robin.
Consumer applications will need to perform deduplication or handle incoming messages in an idempotent manner.
If a message is delivered to a consumer and then requeued (because it was not acknowledged before the consumer connection dropped, for example) then RabbitMQ will set the redelivered flag on it when it is delivered again (whether to the same consumer or a different one).
If a consumer determines that it cannot handle a message then it can reject it using basic.reject (or basic.nack), either asking the server to requeue it, or not.
Reliability
Acknowledgment
Message acknowledgments are turned on by default. If consumer dies without sending an ack, RabbitMQ will understand that a message wasn’t processed fully and will redeliver it to another consumer. That way you can be sure that no message is lost, even if the workers occasionally die.
(kong)该特性需要在consumer的代码中显式的发送ack,如:ch.basic_ack(delivery_tag = method.delivery_tag);再比如OpenStack中olso.messaging中的代码。
There aren’t any message timeouts; RabbitMQ will redeliver the message only when the worker connection dies. It’s fine even if processing a message takes a very, very long time.
Please refer to http://stackoverflow.com/questions/7063224/how-can-i-recover-unacknowledged-amqp-messages-from-other-channels-than-my-conne if you’re interested in the ack mechanism.
Confirmation
Two things are required to make sure that messages aren’t lost if RabbitMQ server stops: we need to mark both the exchange/queue and messages as durable. But there is still a short time window when RabbitMQ has accepted a message and hasn’t saved it yet. If you need a stronger guarantee then you can use publisher confirms.
For routable messages, the basic.ack is sent when a message has been accepted by all the queues. For persistent messages routed to durable queues, this means persisting to disk. For mirrored queues, this means that all mirrors have accepted the message.
Distributed Broker
Sometimes however it is necessary or desirable to make the RabbitMQ broker itself distributed. There are three ways in which to accomplish that: with clustering, with federation, and using the shovel.
Heartbeat
Heartbeat frames are sent about every timeout / 2 seconds. After two missed heartbeats, the peer is considered to be unreachable. Different clients manifest this differently but the TCP connection will be closed. When a client detects that RabbitMQ node is unreachable due to a heartbeat, it needs to re-connect.
Commands
rabbitmqctl list_queues name messages_ready messages_unacknowledged
rabbitmqctl list_exchanges
rabbitmqctl list_bindings
Oslo.messaging
终于可以用中文写了。
oslo.messaging的产生就不多说了,因为RPC的调用在各个项目中都有,以前各个项目分别维护一坨类似的代码,为了简化工作、方便打包等,社区就把RPC相关的功能作为OpenStack的一个依赖库。另一方面,也为后续支持非AMQP协议的消息中间件(ZeroMQ)的引入打下基础。
其实oslo.messaging库就是把rabbitmq的python库做了封装,考虑到了编程友好、性能、可靠性、异常的捕获等诸多因素。让各个项目的开发者聚焦于业务代码的编写,而不用考虑消息如何发送和接收。这对于各个项目开发者来说当然是好事,但对于一套OpenStack系统的运维人员来说,封装就意味着很多细节被隐藏,为了能够解决消息转发过程中出现的问题,需要再花费时间和精力去理解oslo.messaging的业务逻辑,对于本来就错综复杂的OpenStack核心业务来说,无疑是雪上加霜。
关于oslo.messaging的代码相关的介绍,网上有很多现成的文章,我也不想再花费时间书面总结(其实代码本身就是文档,好好读读代码即可)。但代码本身是枯燥的,所以,这里我就举例说明oslo.messaging的流程。
nova-compute重启虚拟机(cast调用)
在nova-compute重启的时候,系统初始化过程中,如果判断到主机上有虚拟机需要reboot,nova-compute会有如下调用(这个例子中的RPC调用方式其实是一个bug,已被我的同事修复,https://review.openstack.org/#/c/170110/):
self.compute_rpcapi.reboot_instance(context, instance, block_device_info=None, reboot_type=reboot_type)
这里的compute_rpcapi就是一个调用oslo.messaging库的客户端:
VERSION_ALIASES = {
'icehouse': '3.23',
'juno': '3.35',
}
def __init__(self):
super(ComputeAPI, self).__init__()
target = messaging.Target(topic=CONF.compute_topic, version='3.0')
version_cap = self.VERSION_ALIASES.get(CONF.upgrade_levels.compute,
CONF.upgrade_levels.compute)
serializer = objects_base.NovaObjectSerializer()
self.client = self.get_client(target, version_cap, serializer)
def get_client(self, target, version_cap, serializer):
return rpc.get_client(target,
version_cap=version_cap,
serializer=serializer)
......
def get_client(target, version_cap=None, serializer=None):
assert TRANSPORT is not None
serializer = RequestContextSerializer(serializer)
return messaging.RPCClient(TRANSPORT,
target,
version_cap=version_cap,
serializer=serializer)
这里有几个概念:
target:作为消息发送者,需要在target中指定消息要发送到的exchange, binding-key, consumer等信息(这些概念可能与target对象属性不一样)
serializer:负责消息的序列化处理。就是负责把Nova中的对象转换成可以在网络中传送的格式。
TRANSPORT:处理消息发送的抽象层。根据rpc_backend的配置确定真正处理消息发送的driver。一般我们会用到这个:rabbit = oslo_messaging._drivers.impl_rabbit:RabbitDriver。对于RabbitDriver,其相关配置项都在/oslo_messaging/_drivers/impl_rabbit.py中,它内部会维护一个connection pool,管理Connection对象。
此时,我们知道,一个messaging客户端的初始化,可以确定这么几个事情:消息发到哪?消息由谁来发?消息如何做序列化?……但是,我们还缺一个最重要的,消息在哪?
别急,这只是一个RPC客户端的初始化过程……
我们接着看nova-compute通过RPC重启虚拟机:
def reboot_instance(self, ctxt, instance, block_device_info,
reboot_type):
version = '3.0'
cctxt = self.client.prepare(server=_compute_host(None, instance),
version=version)
cctxt.cast(ctxt, 'reboot_instance',
instance=instance,
block_device_info=block_device_info,
reboot_type=reboot_type)
解释一下:
1、RPCClient的prepare函数,是根据客户端的需求,对target重新配置一下,比如这里,更新了客户端中的server、version属性(server就对应于RabbitMQ中的consumer,也就是一个计算节点)。说明该请求是针对某个特定的consumer,而不是把消息扔到queue里,随机选择consumer处理。该函数返回一个RPCClient的包装类(_CallContext)对象。
2、cast。熟悉OpenStack消息队列的都知道,RPC消息发送分为同步和异步,这个背景知识我也不再赘述。这里的cast就是发送一个异步消息。
def cast(self, ctxt, method, **kwargs):
"""Invoke a method and return immediately. See RPCClient.cast()."""
msg = self._make_message(ctxt, method, kwargs)
ctxt = self.serializer.serialize_context(ctxt)
if self.version_cap:
self._check_version_cap(msg.get('version'))
try:
self.transport._send(self.target, ctxt, msg, retry=self.retry)
except driver_base.TransportDriverError as ex:
raise ClientSendError(self.target, ex)
3、消息组装。msg就是要发送的消息体,里面都有啥呢?几个部分:
method,接收端函数的名称;
args,接收端函数的参数,参数会做序列化处理;
namespace,就是target中的namespace属性;
version,target中的version,这个version要与之前的version_cap兼容,major要一致,minor要小于或等于version_cap,即:rpcapi中的函数版本不能大于该客户端version_cap指定的版本;这个version很大的作用是为了升级时版本兼容,具体可参见团队一个同事关于升级的一篇博客:这里
4、消息的发送。这里调用了上述TRANSPORT的方法:
def _send(self, target, ctxt, message,
wait_for_reply=None, timeout=None,
envelope=True, notify=False, retry=None):
class Context(object):
def __init__(self, d):
self.d = d
def to_dict(self):
return self.d
context = Context(ctxt)
msg = message
if wait_for_reply:
msg_id = uuid.uuid4().hex
msg.update({'_msg_id': msg_id})
LOG.debug('MSG_ID is %s', msg_id)
msg.update({'_reply_q': self._get_reply_q()})
rpc_amqp._add_unique_id(msg)
rpc_amqp.pack_context(msg, context)
if envelope:
msg = rpc_common.serialize_msg(msg)
if wait_for_reply:
self._waiter.listen(msg_id)
try:
with self._get_connection(rpc_amqp.PURPOSE_SEND) as conn:
if notify:
conn.notify_send(self._get_exchange(target),
target.topic, msg, retry=retry)
elif target.fanout:
conn.fanout_send(target.topic, msg, retry=retry)
else:
topic = target.topic
if target.server:
topic = '%s.%s' % (target.topic, target.server)
conn.topic_send(exchange_name=self._get_exchange(target),
topic=topic, msg=msg, timeout=timeout,
retry=retry)
if wait_for_reply:
result = self._waiter.wait(msg_id, timeout)
if isinstance(result, Exception):
raise result
return result
finally:
if wait_for_reply:
self._waiter.unlisten(msg_id)
代码有点多,几点解释:
1、对于cast调用,没有wait_for_reply,没有timeout,没有notify,也说明cast方式不需要等待consumer的消费和返回值。
2、给msg消息随机生成一个唯一标识:_unique_id,并且将context中的信息扔到msg里。然后重新组装msg成如下格式:
{
'oslo.version': 2.0(目前是)
'oslo.message': 原始msg
}
这就是最终在RabbitMQ中传递的消息体。
3、从上述提到的connection pool中获取一个Connection对象,调用其topic_send方法,注意里面的参数,指定了exchange的名称、binding-key、消息体等参数。
4、Connection对象,前面提到,但没细讲。这个对象封装了对RabbitMQ的连接。
5、topic_send方法,就是初始化一个TopicPublisher对象,发消息发到RabbitMQ的broker中。 对于RabbitDriver来说,有很多类似于TopicPublisher的类,比如:DirectPublisher、FanoutPublisher,它们都是继承自Publisher(里面方法就是对RabbitMQ python库的直接调用),但表示不同的消息发送行为(从名字就能看出来)。但没有本质区别,只是不同类型的exchange属性不同而已。从topic_send方法也能看出来oslo.messaging在RabbitMQ python库自身消息发送之外,做了两个事儿:一是重试机制,二是对异常的捕获。这也是RabbitMQ tutorial中RPC章节的最后所建议的。
OK,到这里,一个cast消息的发送就结束了。本来说不讲oslo.messaging的代码实现,但发现绕开代码讲实现有点耍流氓,所以还是贴了很多代码。但对于oslo.messaging的学习,不能钻进代码太深(其实对于任何项目的学习都是这样),到每一个关键步骤,最好适时的从代码中出来,从全局视角再思考一下整个流程,会对整个机制的理解更深。
call调用
讲完了cast,那么顺便说一下call消息发送的过程。call和cast很像,区别在于:
1、call需要等待consumer处理结束,拿到返回值;
2、call需要考虑超时和捕获异常;
3、对返回消息做反序列化处理;
具体实现中的区别在于:
1、在消息发送之前,给msg增加两个属性:_msg_id和_reply_q,前者是随机生成(注意要跟unique id区分开来),用于区分不同发送端发送的消息,后者是为了给consumer提示,处理结果该发给谁,其实就是发送端维护的临时exchange和queue,用于获取返回的消息。
2、发送端会创建一个全局的ReplyWaiter对象(在每个发送端共用),用于监听上述临时的queue,对收到的消息进行处理(它本身就是接收到消息的callback)。
def __call__(self, message):
message.acknowledge()
incoming_msg_id = message.pop('_msg_id', None)
self.waiters.put(incoming_msg_id, message)
可以看到首先发送ack,然后把消息存储起来。ReplyWaiter全局对象维护着每个msg的id和返回结果,每个发送端只关心与自己相关的msg。返回结果中可能包含的字段:failure、ending、result,注意,每个发送端都会有超时处理和重复消息处理。
关于call调用有一张经典的图:
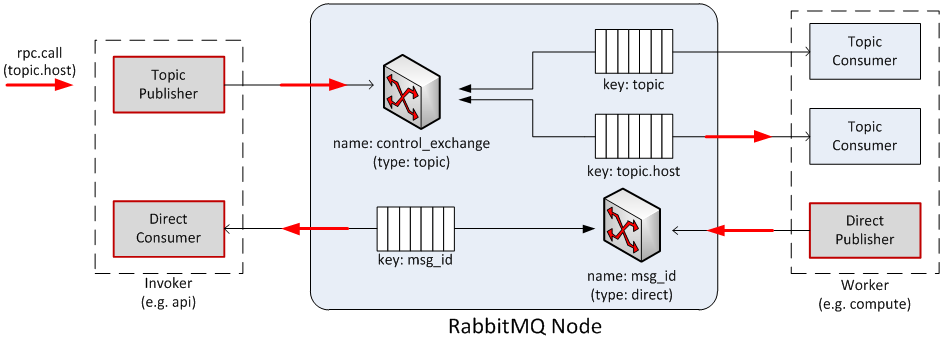
接收端,以nova-compute为例
上面讲了那么多,都是作为RPC客户端的行为,RPC客户端的调用,需要RPC服务端提供接口服务。在nova-compute服务初始化方法中(其他作为接收端的服务也类似):
target = messaging.Target(topic=self.topic, server=self.host)
endpoints = [
self.manager,
baserpc.BaseRPCAPI(self.manager.service_name, self.backdoor_port)
]
endpoints.extend(self.manager.additional_endpoints)
serializer = objects_base.NovaObjectSerializer()
self.rpcserver = rpc.get_server(target, endpoints, serializer)
self.rpcserver.start()
......
def get_server(target, endpoints, serializer=None):
assert TRANSPORT is not None
serializer = RequestContextSerializer(serializer)
return messaging.get_rpc_server(TRANSPORT,
target,
endpoints,
executor='eventlet',
serializer=serializer)
几点解释:
1、作为服务端,要在target中定义topic和server,同样需要提供serializer、TRANSPORT、target;
2、endpoints,作为接收端,消息来了如何处理?endpoints就是消息最终处理者,endpoint本身是可调用的,nova-compute本身就是一个endpoint;
3、executor,见下述描述。
transport, dispatcher, executor三者有啥区别呢?引用一句代码注释:
Connect a transport to a dispatcher that knows how to process the message using an executor that knows how the app wants to create new tasks.
通俗一点讲,executor确定接收消息的线程模型,transport负责在消息中间件层面接收消息,dispatcher负责最终的消息处理。都是为了代码逻辑而抽象出来的概念。
一般我们用的executor是eventlet,executor的工作就两件事儿:1、取消息;2、处理消息。
取消息
在取消息之前,transport有一个listen的操作:
def listen(self, target):
conn = self._get_connection(rpc_amqp.PURPOSE_LISTEN)
listener = AMQPListener(self, conn)
conn.declare_topic_consumer(exchange_name=self._get_exchange(target),
topic=target.topic,
callback=listener)
conn.declare_topic_consumer(exchange_name=self._get_exchange(target),
topic='%s.%s' % (target.topic,
target.server),
callback=listener)
conn.declare_fanout_consumer(target.topic, listener)
return listener
可以看到,新建了三个exchange(2个是topic类型,1个是fanout类型)和绑定的队列,并在队列上监听消息,消息的处理是AMQPListener对象。AMQPListener的处理也很简单,不停的从队列中取消息,对消息做去重、解封装(把一些属性抽取出来)后,最终构造成一个AMQPIncomingMessage类型的消息加入内存,等待被处理。
处理消息
在dispatcher处理消息时,首先发送ack,然后根据msg中的method、args、namespace、version等信息(都是上述我们已经熟悉的东西),选择合适的endpoint处理。什么叫合适的endpoint呢?
- endpoint的target属性中namespace、version是否与消息兼容;
- endpoint中是否有对应的method;
endpoint本身是可调用的,后续就是消息的反序列化、调用、序列化(准备返回给调用者)。
OK,我们还有最后一点没提及,消息如何返回给调用者(对于call操作)。根据前面的知识,我们知道call的调用者们会监听一个全局的queue,并且在msg中也给了足够的hints(msg_id和reply_q),最为接收者,消息的返回就很简单了。
def _send_reply(self, conn, reply=None, failure=None,
ending=False, log_failure=True):
if failure:
failure = rpc_common.serialize_remote_exception(failure,
log_failure)
msg = {'result': reply, 'failure': failure}
if ending:
msg['ending'] = True
rpc_amqp._add_unique_id(msg)
# If a reply_q exists, add the msg_id to the reply and pass the
# reply_q to direct_send() to use it as the response queue.
# Otherwise use the msg_id for backward compatibility.
if self.reply_q:
msg['_msg_id'] = self.msg_id
conn.direct_send(self.reply_q, rpc_common.serialize_msg(msg))
else:
conn.direct_send(self.msg_id, rpc_common.serialize_msg(msg))
参考链接
http://docs.openstack.org/developer/oslo.messaging/
https://wiki.openstack.org/wiki/Oslo/Messaging
http://bingotree.cn/?p=207
