Python中的命令行解析工具介绍
本博客所有文章采用的授权方式为 自由转载-非商用-非衍生-保持署名 ,转载请务必注明出处,谢谢。
声明:
本博客欢迎转发,但请保留原作者信息!
新浪微博:@Lingxian_kong
博客地址:孔令贤的博客
微信公众号:飞翔的尘埃
知识星球:飞翔的尘埃
内容系本人学习、研究和总结,如有雷同,实属荣幸!
sys.argv
最简单、最原始的方法就是手动解析了。
import sys
def TestSys():
for arg in sys.argv[1:]:
print (arg)
getopt
getopt模块是原来的命令行选项解析器,支持UNIX函数getopt()建立的约定。它会解析一个参数序列,如sys.argv,并返回一个元祖序列和一个非选项参数序列。目前支持的选项语法包括短格式和长格式选项:-a, -bval, -b val, --noarg, --witharg=val, --witharg val。如果只是简单的命令行解析,getopt还是不错的选择。一个例子如下:
try:
options, remainder = getopt.getopt(sys.argv[1:], 'o:v', ['output=', 'verbose', 'version=',])
except getopt.GetoptError as err:
print 'ERROR:', err
sys.exit(1)
简单说明,如果某个单字符选项需要参数,在他后面加冒号;对于长格式选项,要加等号。如果getopt在输入参数中遇到了’–‘,解析会停止。
argparse
optparse was deprecated since version 2.7 and will not be developed further; development will continue with the argparse module.
argparse是python标准库中的模块,以前的optparse已经废弃。利用argparse,可以完成对命令行的参数定义、解析以及后续的处理。一个很简单的例子如下(文件名prog.py,这个例子其实什么也不做):
import argparse
parser = argparse.ArgumentParser(description="some information here")
args = parser.parse_args()
这样,prog.py就能解析命令行参数了,按照如下方式运行,结果如下:
$ python prog.py
$ python prog.py --help
usage: prog.py [-h]
optional arguments:
-h, --help show this help message and exit
$ python prog.py --verbose
usage: prog.py [-h]
prog.py: error: unrecognized arguments: --verbose
$ python prog.py foo
usage: prog.py [-h]
prog.py: error: unrecognized arguments: foo
其实ArgumentParser函数有很多可选参数,prog、usage、description、epilog分别定义解析器的名称、使用说明、描述、最后的结尾描述。使用parents表示共享同一个父类解析器(这样就可以共享父类解析器的参数),而这个父类解析器通常是如下定义:
parent_parser = argparse.ArgumentParser(add_help=False)
此外,formatter_class定义description的显示格式,取值可以是如下三种,具体示例参见此处:
- RawDescriptionHelpFormatter,
- RawTextHelpFormatter
- ArgumentDefaultsHelpFormatter
其它还有很多参数,此处就不一一列举了。
增加参数
ArgumentParser.add_argument(name or flags...[, action][, nargs][, const][, default][, type][, choices][, required][, help][, metavar][, dest])
每个参数解释如下:
name or flags - 参数的名字.
action - 遇到参数时的动作,默认值是store。store_const,表示赋值为const;append,将遇到的值存储成列表,也就是如果参数重复则会保存多个值; append_const,将参数规范中定义的一个值保存到一个列表;count,存储遇到的次数;此外,也可以继承argparse.Action自定义参数解析;
nargs - 参数的个数,可以是具体的数字,或者是?号,当不指定值时对于Positional argument使用default,对于Optional argument使用const;或者是*号,表示0或多个参数;或者是+号表示1或多个参数.
const - action和nargs所需要的常量值.
default - 不指定参数时的默认值.
type - 参数的类型.
choices - 参数允许的值.
required - 可选参数是否可以省略(仅针对optionals).
help - 参数的帮助信息,当指定为argparse.SUPPRESS时表示不显示该参数的帮助信息.
metavar - 在usage说明中的参数名称,对于必选参数默认就是参数名称,对于可选参数默认是全大写的参数名称.
dest - 解析后的参数名称,默认情况下,对于可选参数选取最长的名称,中划线转换为下划线.
一些示例:
# 参数名称为echo
parser.add_argument("echo", help="echo the string you use here")
# 可以增加类型
parser.add_argument("square", help="display a square of a given number",
type=int)
# 可选参数前面多了--符号,-v是简写形式,store_true说明碰到该参数时保存为true,否则就是false
parser.add_argument("-v", "--verbose", help="increase output verbosity",
action="store_true")
# 当然,也可以这样写,规定了可选参数的类型和取值范围
parser.add_argument("-v", "--verbosity", type=int, choices=[0, 1, 2],
help="increase output verbosity")
# count表示遇到该参数几次,值就加几,默认值是0
parser.add_argument("-v", "--verbosity", action="count", default=0,
help="increase output verbosity")
增加互斥类型的参数:
group = parser.add_mutually_exclusive_group()
group.add_argument("-v", "--verbose", action="store_true")
group.add_argument("-q", "--quiet", action="store_true")
如果必选参数的值以-开头,需要在输入命令时特殊处理:
>>> parser = argparse.ArgumentParser(prog='PROG')
>>> parser.add_argument('foo', nargs='?')
>>> parser.parse_args(['--', '-f'])
Namespace(foo='-f')
Sub-commands
将多个命令组合进一个程序中,使用子解析器来处理命令行的每个部分。就像svn,以及OpenStack各个组件那样。
ArgumentParser.add_subparsers([title][, description][, prog][, parser_class][, action][, option_string][, dest][, help][, metavar])
>>> # create the top-level parser
>>> parser = argparse.ArgumentParser(prog='PROG')
>>> parser.add_argument('--foo', action='store_true', help='foo help')
>>> subparsers = parser.add_subparsers(help='sub-command help')
>>>
>>> # create the parser for the "a" command
>>> parser_a = subparsers.add_parser('a', help='a help')
>>> parser_a.add_argument('bar', type=int, help='bar help')
>>>
>>> # create the parser for the "b" command
>>> parser_b = subparsers.add_parser('b', help='b help')
>>> parser_b.add_argument('--baz', choices='XYZ', help='baz help')
>>>
>>> # parse some argument lists
>>> parser.parse_args(['a', '12'])
Namespace(bar=12, foo=False)
>>> parser.parse_args(['--foo', 'b', '--baz', 'Z'])
Namespace(baz='Z', foo=True)
Partial parsing
ArgumentParser.parse_known_args(args=None, namespace=None)
其实与parse_args()类似,但当碰到多余的参数时不抛出错误,而是返回一个二元组。
>>> parser = argparse.ArgumentParser()
>>> parser.add_argument('--foo', action='store_true')
>>> parser.add_argument('bar')
>>> parser.parse_known_args(['--foo', '--badger', 'BAR', 'spam'])
(Namespace(bar='BAR', foo=True), ['--badger', 'spam'])
对于argparse的高级使用,建议直接看一下OpenStack中Oslo组件的源码,会受益匪浅的。
docopt
docopt就比较强大了,它是根据你自己写的help messages(文档描述),自动为你生成parser。使用之前需要下载相应的库,这里有个界面可以试用一下docopt的强大,借用官方的一个例子:
"""Usage: arguments_example.py [-vqrh] [FILE] ...
arguments_example.py (--left | --right) CORRECTION FILE
Process FILE and optionally apply correction to either left-hand side or
right-hand side.
Arguments:
FILE optional input file
CORRECTION correction angle, needs FILE, --left or --right to be present
Options:
-h --help
-v verbose mode
-q quiet mode
-r make report
--left use left-hand side
--right use right-hand side
"""
from docopt import docopt
if __name__ == '__main__':
arguments = docopt(__doc__)
print(arguments)
文档描述有两个部分:Usage和Option .
Usage: 以一个空行结束,冒号后面的第一个单词作为程序的名称。名称后面就是参数的描述,可以包括:
- 必选参数。是全大写的单词或尖括号括起来的的单词
- 可选参数。需要注意的是,-oiv可以表示-o -i -v。可选参数的形式可以是–input=FILE or -i FILE or even -iFILE.
- 子命令。
[]表示可选参数,如my_program.py [-hvqo FILE];
( )表示必选参数,以及没有包含在[]中都作为必选参数。
|表示互斥参数
… 表示接收多个参数值,如my_program.py FILE ...
Options:可选参数的描述。
每一行以- or –开头;同一行相同可选参数以空格隔开;两个或以上的空格分隔描述;可以定义默认值([default: value]);
需要注意的是,docopt不能完成argparse具有的参数值校验的功能。目前docopt已经被移植到了Ruby, PHP等语言
更多的例子可以参考这里
clize
clize也比较强大,利用装饰器将函数转换成命令行解析器。github地址:https://github.com/epsy/clize,一个例子:
#!/usr/bin/env python
from clize import run
from sigtools.modifiers import autokwoargs
@autokwoargs
def echo(word, prefix='', suffix=''):
"""Echoes text back
word: One word or quoted string to echo back
prefix: Prepend this to each line in word
suffix: Append this to each line in word
"""
if prefix or suffix:
return '\n'.join(prefix + line + suffix
for line in word.split('\n'))
return word
if __name__ == '__main__':
run(echo)
生成的帮助文档如下:
$ ./echo.py --help
Usage: ./echo.py [OPTIONS] word
Echoes text back
Positional arguments:
word One word or quoted string to echo back
Options:
--prefix=STR Prepend this to each line in word(default: )
--suffix=STR Append this to each line in word(default: )
Other actions:
-h, --help Show the help
但个人感觉clize与argparse和docopt比起来,支持的功能相对还比较少,而且不容易上手(因为要熟悉相关的各种装饰器及其参数的使用),要支持高级解析功能,代码写起来比较费劲。
Google开源的库,Fire
Google出手,必是精品,强烈推荐。废话不多说,可以直接看github上的介绍。
Github地址:https://github.com/google/python-fire
如何使用:https://github.com/google/python-fire/blob/master/doc/using-cli.md
argparse在OpenStack中的使用
OpenStack各个组件都有相应的命令行工具,以novaclient为例,就充分利用了argparse来实现命令行的解析。
在novaclient脚本的开始处,就是argparse的典型用法:
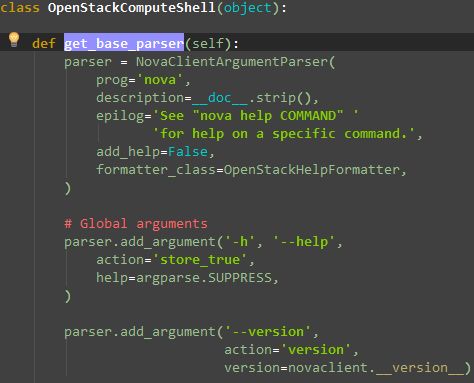
其中NovaClientArgumentParser就是继承自argparse.ArgumentParser,接下来就是添加Sub-commands,然后对命令行参数进行解析:
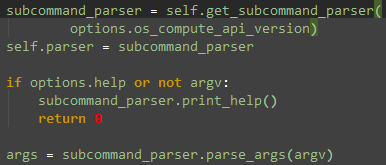
如果熟悉了上面对argparse的讲解,基本上就可以开始进行novaclient的开发了。
