Heat中的AutoScaling(1)
本博客所有文章采用的授权方式为 自由转载-非商用-非衍生-保持署名 ,转载请务必注明出处,谢谢。
声明:
本博客欢迎转发,但请保留原作者信息!
新浪微博:@Lingxian_kong
博客地址:孔令贤的博客
微信公众号:飞翔的尘埃
知识星球:飞翔的尘埃
内容系本人学习、研究和总结,如有雷同,实属荣幸!
本文主要讲AutoScaling,关于CloudFormation和Heat,之前的博客已经有讲过,本文不做赘述。
AutoScaling in AWS
AutoScaling的概念最早出现在AWS,Auto Scaling 是一项 Web 服务,旨在根据用户定义的策略、时间表和运行状况检查启动或终止 EC2 实例。在典型的商业场景中,在 Web 应用程序开始获得更多流量时,您将添加更多的服务器或增加现有服务器的大小来应对额外负载。同样,当 Web 应用程序的流量开始减少时,您将终止未充分利用的服务器,或者减少现有服务器的大小。根据您的基础设施,每次进行垂直扩展时可能都会涉及更改服务器配置。如果使用水平扩展,您仅需根据应用程序的需求增加或减少服务器数量。将根据一些因素来决定进行垂直扩展还是水平扩展,如使用案例、成本、性能和基础设施。
Auto Scaling 可以通过以下几种方式扩展计算资源:
- 根据指定条件动态扩展(例如,增加 Amazon EC2 实例的 CPU 利用率)
- 根据定义的计划以可预测的方式进行扩展(例如,在每周星期五 13:00:00 扩展)
- 根据用户使用安排,改变伸缩组大小
- 根据用户使用安排,立即执行策略
除了按需启动和终止 EC2 实例,Auto Scaling 还可以确保 Auto Scaling 组内的 EC2 实例以良好状况运行。Auto Scaling 在 Auto Scaling 组的当前实例上进行定期运行状况检查,如果发现实例运行状况不佳,它将终止该实例,并启动新实例。这有助于保持定义的最小数量(或指定的所需数量)的运行实例。
AutoScaling通常使用 Amazon CloudWatch 标识指标和创建警报,使用Elastic Load Balancing来对组内虚拟机进行负载均衡。
简单流程
AutoScaling工作方式如下图:
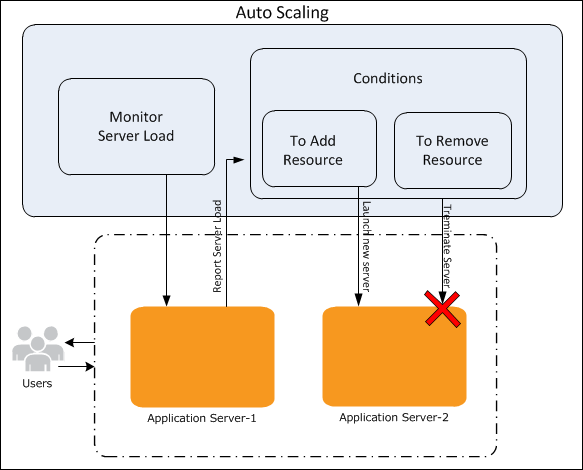
使用流程大致如下(以下使用AWS命令行):
1、创建启动配置
as-create-launch-config MyLC --image-id ami-2272864b --instance-type m1.large
2、创建 Auto Scaling 组
定义启动配置后,您随时可以创建 Auto Scaling 组。要使用 as-create-auto-scaling-group 创建 Auto Scaling 组,您必须为该组指定名称,还要指定启动配置、一个或多个可用区域、组的最大容量和最小容量。
as-create-auto-scaling-group MyGroup --launch-configuration MyLC --availability-zones us-east-1a --min-size 1 --max-size 1
3、验证
使用as-describe-auto-scaling-groups 命令来确认 MyGroup Auto Scaling 组是否存在,使用as-describe-auto-scaling-instances验证 MyGroup 中是否包含 EC2 实例
4、删除EC2实例和 Auto Scaling 组
先从 Auto Scaling 组移除 EC2 实例,然后删除 Auto Scaling 组,最后删除启动配置
as-update-auto-scaling-group MyGroup --min-size 0 --max-size 0
as-delete-auto-scaling-group MyGroup
as-delete-launch-config MyLC
动态扩展
因为在实际情况下使用动态扩展的情况较多,所以附上一张动态扩展的图:
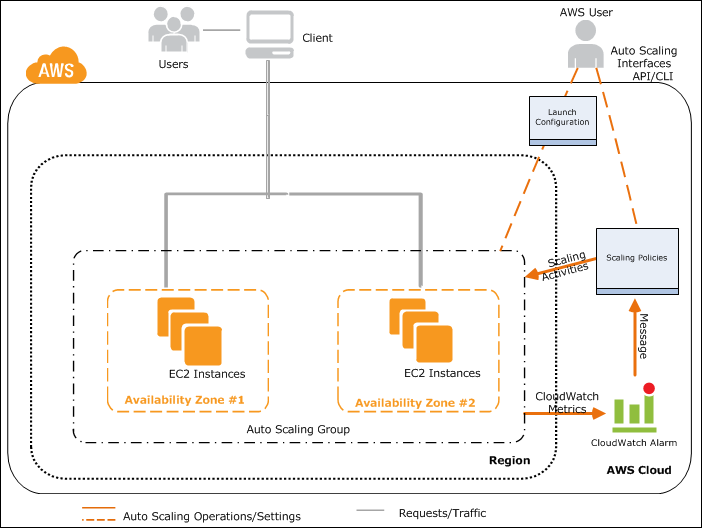
假定用户已完成以下操作:
- 已通过提供启动 EC2 实例所需的所有信息创建了启动配置。
- 已通过定义 EC2 实例的最大容量、最小容量和(可选)所需容量创建了 Auto Scaling 组。
- 已创建 Amazon CloudWatch 警报并定义了要监控的指标。
- 已创建两个扩展策略(一个用于增加实例,另一个用于减少实例),并将策略与警报相关联。
- 已将扩展策略与 Auto Scaling 组相关联。
以下流程从在 Auto Scaling 组中启动 EC2 实例开始。
- 在 Auto Scaling 组启动用于应用程序的所有 EC2 实例后,该应用程序可以开始与用户通信。
- 在用户发送请求和应用程序实例接收请求的过程中,Amazon CloudWatch 将监控 Auto Scaling 组中所有实例的指定指标。
- 随着对应用程序需求的增加或减少,指定的指标也随之变化。
- 指标的变化将引发 CloudWatch 警报执行操作。该操作是向用于减少实例的策略或用于增加实例的策略发送消息,具体取决于违反的指标。
- 然后,收到消息的 Auto Scaling 策略将引发 Auto Scaling 组中的扩展活动。
- 该 Auto Scaling 流程将继续进行,直到删除策略或终止 Auto Scaling 组。
相关的命令示例:
# 创建伸缩组
as-create-auto-scaling-group my-test-asg --launch-configuration my-test-lc --availability-zones "us-east-1e" --max-size 5 --min-size 1
# 创建两个策略
as-put-scaling-policy my-scaleout-policy -–auto-scaling-group my-test-asg --adjustment=30 --type PercentChangeInCapacity
as-put-scaling-policy my-scalein-policy –auto-scaling-group my-test-asg --adjustment=-2 --type ChangeInCapacity
# 在CloudWatch中创建两个与策略关联的告警
mon-put-metric-alarm --alarm-name AddCapacity --metric-name CPUUtilization --namespace AWS/EC2 --statistic Average --period 120 --threshold 80 --comparison-operator GreaterThanOrEqualToThreshold --dimensions AutoScalingGroupName=my-test-asg --evaluation-periods 2 --alarm-actions arn:aws:autoscaling:us-east-1:123456789012:scalingPolicy:ac542982-cbeb-4294-891c-a5a941dfa787:autoScalingGroupName/ my-test-asg:policyName/my-scaleout-policy
mon-put-metric-alarm --alarm-name RemoveCapacity --metric-name CPUUtilization --namespace AWS/EC2 --statistic Average --period 120 --threshold 40 --comparison-operator LessThanOrEqualToThreshold --dimensions AutoScalingGroupName=my-test-asg --evaluation-periods 2 --alarm-actions arn:aws:autoscaling:us-east-1:123456789012:scalingPolicy:4ee9e543-86b5-4121- b53b-aa4c23b5bbcc:autoScalingGroupName/ my-test-asg:policyName/my-scalein-policy
计划扩展
按计划扩展使您可以按照可预测的负载变化来扩展应用程序。例如,您的 Web 应用程序的流量会在每周的星期三开始增加,并在星期四保持高流量状态,然后在星期五开始下降。您可以根据 Web 应用程序的可预测流量模式来计划扩展活动。
创建计划操作来扩展您的 Auto Scaling 组的流程如下:
- 创建启动配置
- 创建 Auto Scaling 组
- 创建仅用于一次扩展的计划操作,或者重复使用该计划进行扩展
- 验证已为您的 Auto Scaling 组计划扩展操作
相关命令:
# 创建一个在某个时间点执行活动的计划
as-put-scheduled-update-group-action ScaleUp --auto-scaling-group my-test-asg --start-time "2013-05-12T08:00:00Z" --desired-capacity 3
# 创建一个可重复执行的计划
as-put-scheduled-update-group-action scaleup-schedule-year --auto-scaling-group my-test-asg --recurrence “30 0 1 1,6,12 0” --desired-capacity 3
在CloudFormation中的使用
上面说了,AutoScaling是AWS的独立服务,对外提供开放的API。在CloudFormation中使用这个服务时,涉及到资源的定义。主要由以下几个:
- AWS::AutoScaling::AutoScalingGroup
- AWS::AutoScaling::LaunchConfiguration
- AWS::AutoScaling::ScalingPolicy,一般与 Amazon CloudWatch 告警配合使用
- AWS::AutoScaling::Trigger,已不建议使用
- AWS::CloudWatch::Alarm,这个资源其实是调用 CloudWatch 服务创建
AutoScaling in OpenStack Icehouse
在Heat中实现AutoScaling,也有几个资源定义:OS::Heat::CWLiteAlarm, AWS::AutoScaling::LaunchConfiguration, AWS::AutoScaling::AutoScalingGroup, AWS::AutoScaling::ScalingPolicy, OS::Ceilometer::Alarm, OS::Ceilometer::CombinationAlarm
这里简单介绍下
OS::Heat::CWLiteAlarm和OS::Ceilometer::Alarm,前者在资源创建时会创建watch_rule记录,而后者会到Ceilometer创建Alarm资源,同时为了前向兼容,也会创建watch_rule记录,但state是CEILOMETER_CONTROLLED,此时像cfn-push-stats这样的脚本在调用heat-cloudwatch-api时就会将数据转发给Ceilometer。watch_rule记录是在heat engine服务启动的循环任务中用到的,在循环任务中会调用WatchRule的evaluate方法。
流程图如下:
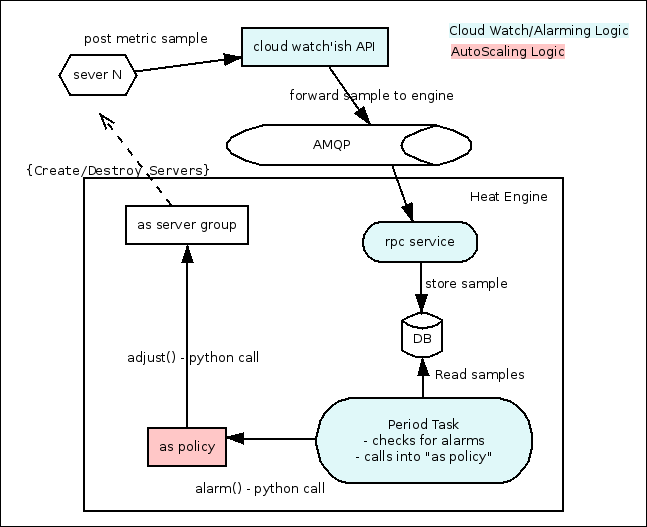
以官方给出的模板为例,模块中定义的资源依赖关系如下:

资源的创建顺序从下往上。
1、LaunchConfig仅仅在DB中记录;
2、创建Group,其实是构造一个template,根据template创建一个内层的stack,stack里面的虚拟机属性中有个Tags字段,Tags的值是一个列表(元素是dict),{'key': 'metering.groupname', 'value': <Group的标识>}
3、Policy的创建有点类似于WaitCondition,对Policy资源的引用其实就是一个URL(以/signal标识)
4A、创建Alarm,就是增加一条watch_rule数据库记录(使用OS::Heat::CWLiteAlarm时),还记的每个stack都有一个线程池么?在循环任务执行过程中,根据DB中的watch-data,对Alarm的触发条件进行判断,更新新的状态,如果该状态对应有action,则调用。那么watch-data的数据从哪来?其实,Heat提供了部分CloudWatch的API,其中就有一个put_metric_data,会更新watch-data的数据。
4B、如果使用Ceilometer的Alarm(OS::Ceilometer::Alarm,这个是后面的发展趋势),则是直接调用Ceilometer API创建alarm,将原来在Heat中的watch-rule循环任务,交由Ceilometer实现。
AutoScaling in Future
看完上述的讲解,会发现,在AWS中Autoscaling是个独立的服务,提供独立的API。但在Heat中只能作为一个stack资源被使用。所以,在Juno版本中,Heat会实现AutoScaling API,相关的bp已经被接纳,敬请期待!
